처음 보인 증상은 단순했습니다. 다운로드는 끝난 것처럼 보였지만, 파일을 열면 ZIP이 정상적으로 풀리지 않았습니다. 겉으로만 보면 압축 포맷이나 CSV 생성 로직이 잘못된 것처럼 보였습니다.
하지만 실제로 좁혀야 했던 것은 포맷보다 응답의 수명주기였습니다. 이 기능은 CSV를 한 번에 만들어 반환하는 API가 아니라, CSV를 ZIP 스트림으로 감싸 브라우저에 내려주는 long-running response였습니다. ZIP은 마지막 종료 레코드까지 기록되어야 정상 파일이 됩니다. 중간에 응답이 끊기면 브라우저는 파일을 받은 것처럼 보여도 ZIP 입장에서는 아직 끝나지 않은 파일이 됩니다.
그래서 이 문제를 “파일이 깨졌다”로 보지 않았습니다. 더 정확한 질문은 왜 응답이 ZIP의 마지막 write까지 살아 있지 못했는가였습니다. 그 질문으로 다시 보면 Tomcat async timeout, offset paging, 반복 lookup, client disconnect가 같은 다운로드 경로 안에서 서로 영향을 주고 있었습니다.
파일 손상처럼 보였지만, 실제로는 응답이 먼저 끝났습니다

처음 의심한 위치는 공통 export helper였습니다. BackOfficeExportResponseHelper는 StreamingResponseBody를 반환했고, 실제 export 작업은 Spring MVC async 처리 경로에서 실행되고 있었습니다. helper는 응답 헤더를 세팅하고, export generator에 output stream을 넘긴 뒤 마지막에 flush하는 단순한 구조였습니다.
문제는 helper의 코드 자체보다 그 코드가 놓인 실행 경로였습니다. StreamingResponseBody는 응답 생성을 별도 async task로 넘기기 때문에, 작업 시간이 길어지면 애플리케이션 로직이 아직 쓰는 중이어도 servlet async timeout의 영향을 받습니다. 작은 CSV에서는 이 차이가 드러나지 않습니다. 하지만 수십 초 이상 열려 있는 export에서는 response lifecycle이 먼저 문제가 됩니다.
ZIP은 마지막 Central Directory가 기록되어야 완전한 파일이 됩니다. async timeout이 먼저 발생하면, 브라우저는 응답을 받은 것처럼 보여도 ZIP 파일은 마지막 구조를 갖추지 못합니다. 그래서 사용자가 보는 증상은 “압축 파일 손상”이지만, 서버에서 봐야 할 원인은 응답이 포맷 종료 지점까지 유지되지 못한 문제였습니다.
이 차이를 분리하지 않으면 엉뚱한 곳을 고치게 됩니다. CSV escape나 압축 레벨을 확인해도, 실제 실패 지점이 response close 이전이라면 같은 증상은 다시 발생합니다. 이번 작업에서는 포맷 생성 로직보다 응답이 어디까지 살아 있었는지, 그리고 마지막 write까지 도달하지 못하게 만든 지연 요인이 무엇인지부터 나눠 봤습니다.
timeout 증설은 해법에서 먼저 제외했습니다
가장 쉬운 대응은 timeout 값을 늘리는 것이었습니다. 하지만 timeout 증설은 실패 시점을 뒤로 미룰 뿐, 구조를 바꾸지는 않습니다. 뒤 페이지로 갈수록 조회 비용이 증가하고, 반복 lookup이 붙고, 응답 수명은 여전히 async timeout에 묶여 있다면 같은 문제는 더 큰 데이터에서 다시 발생합니다.
| 대안 | 장점 | 버린 이유 |
|---|---|---|
| timeout 증설 | 변경 범위가 가장 작습니다. | 응답 수명과 조회 구조 문제를 그대로 둔 채 실패 시점만 늦춥니다. |
| 비동기 export job + 다운로드 링크 | 요청-응답 경로 밖에서 긴 작업을 처리할 수 있습니다. | 프론트엔드 계약과 운영 흐름까지 함께 바뀌어야 했고, 당시 문제 범위보다 변경이 컸습니다. |
| 현재 다운로드 UX 유지 + 응답/조회 구조 수정 | 사용자 계약을 유지하면서 직접 원인을 줄일 수 있습니다. | servlet thread를 더 오래 점유하는 비용은 남습니다. |
이번 작업에서는 세 번째 방식을 선택했습니다. 목적은 모든 export를 완전한 batch system으로 바꾸는 것이 아니었습니다. 이미 운영 중인 다운로드 UX를 유지하면서, 손상 ZIP을 만들던 직접 원인과 가속 요인을 먼저 줄이는 것이 더 현실적인 선택이었습니다.
수정은 세 갈래로 나눴습니다
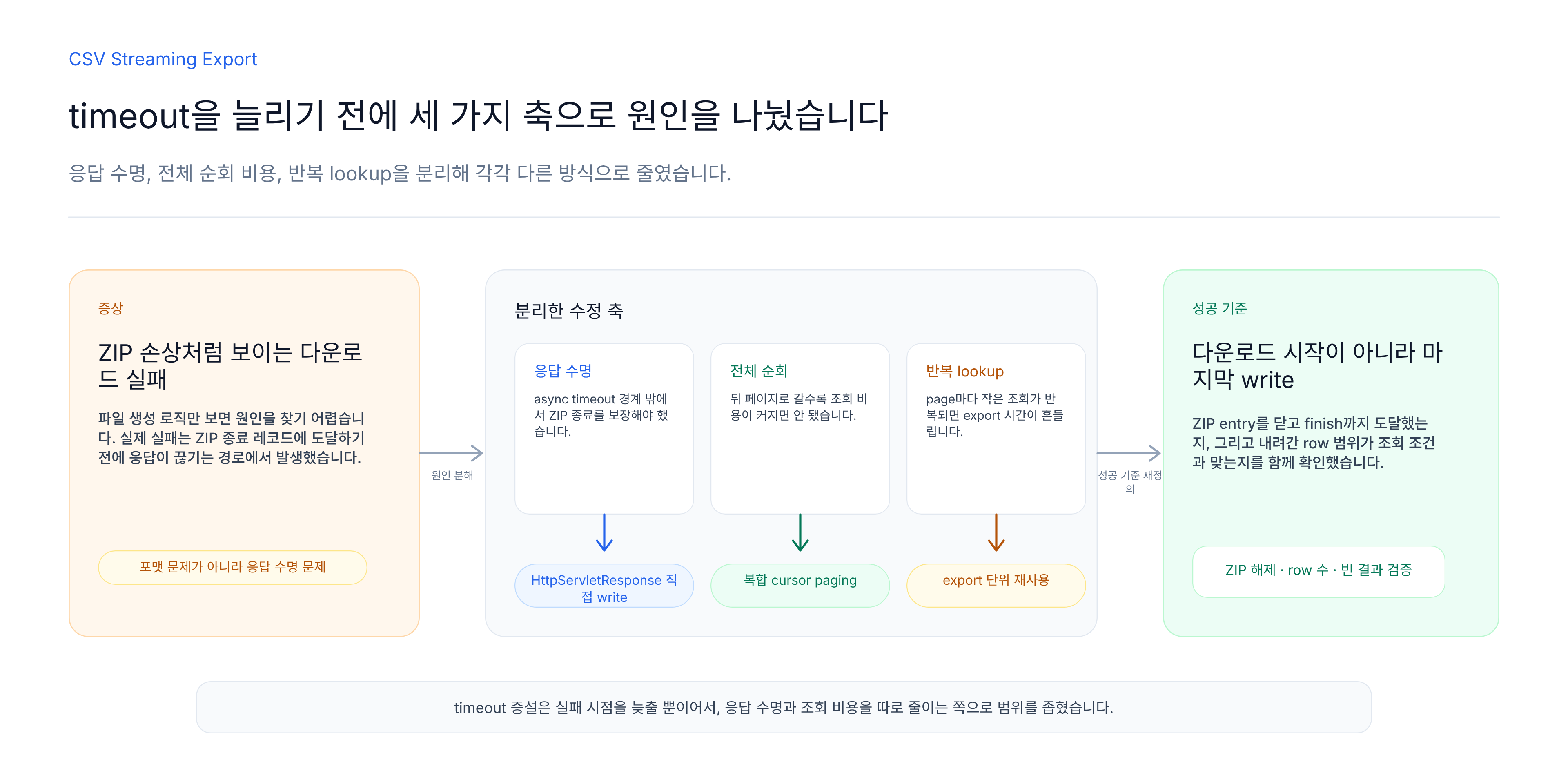
문제를 한 번에 “export가 느리다”로 묶으면 수정도 흐려집니다. 그래서 원인을 세 갈래로 나눴습니다.
- 응답이 마지막 write까지 살아 있어야 합니다.
- 전체 순회 조회의 비용이 뒤 페이지로 갈수록 커지면 안 됩니다.
- 페이지마다 반복되는 lookup이 export 시간을 흔들면 안 됩니다.
이 셋은 서로 다른 문제입니다. 응답 수명주기는 servlet 처리 모델의 문제이고, paging은 DB access pattern의 문제이며, lookup 반복은 데이터 조립 방식의 문제입니다. 하나만 고쳐서는 안정적인 export가 되지 않았습니다.
응답 종료 책임을 애플리케이션 안으로 가져왔습니다
StreamingResponseBody를 제거하고 HttpServletResponse에 직접 write하도록 바꿨습니다. 이 변경의 핵심은 sync 방식이 더 빠르다는 뜻이 아닙니다. ZIP을 여는 시점부터 마지막 종료 지점까지 같은 요청 흐름 안에서 응답 생명주기를 관리하겠다는 뜻입니다.
기존 경로에서는 export generator가 아직 쓰는 중이어도 servlet async timeout이 먼저 개입할 수 있었습니다. 직접 write 경로로 옮기면 async timeout 경계에서 응답이 끊기는 문제를 피하고, ZIP stream의 종료 순서를 애플리케이션 코드 안에서 명확히 관리할 수 있습니다.
구현에서는 임시 파일을 만들지 않고 ZIP entry를 연 뒤, UTF-8 BOM과 header를 먼저 쓰고 row를 페이지 단위로 흘려보내도록 했습니다. 각 page 처리 후에는 적절한 단위로 flush했습니다. 모든 데이터를 메모리에 쌓아 둔 뒤 한 번에 보내는 방식이 아니라, 조회한 만큼 직렬화하고 바로 내려보내는 흐름으로 정리했습니다.
1. response header를 설정한다.
2. ZipOutputStream을 연다.
3. CSV entry를 생성한다.
4. header와 row를 page 단위로 쓴다.
5. page 경계에서 flush한다.
6. 모든 row를 쓴 뒤 closeEntry와 finish 순서로 ZIP을 정상 종료한다.이 흐름에서 마지막 6번은 별도로 봐야 했습니다. export의 성공은 첫 byte가 나갔는지가 아니라, 마지막 종료 지점까지 도달했는지로 판단해야 했습니다. 특히 flush는 중간 데이터를 밀어내는 동작이지 ZIP 파일의 완성을 보장하는 동작이 아닙니다. 그래서 page 단위 flush와 ZIP 종료 처리를 분리해서 봤고, write 도중 예외가 발생했을 때 어느 단계에서 끊겼는지 로그로 남기도록 기준을 잡았습니다.
offset paging을 cursor paging으로 바꿨습니다
응답 수명 문제를 정리해도 조회가 뒤로 갈수록 느려지면 같은 문제가 반복됩니다. 기존 offset paging은 뒤 페이지로 갈수록 앞의 row를 계속 건너뛰어야 했습니다. 관리 화면처럼 얕은 페이지를 탐색할 때는 괜찮지만, export처럼 전체 데이터를 끝까지 순회하는 작업에는 맞지 않았습니다.
그래서 credit history export는 (created_at, ledger_id) 복합 cursor를 기준으로 다시 조회하도록 바꿨습니다. cursor paging의 목적은 첫 페이지를 더 빠르게 만드는 것이 아니라, 마지막 페이지까지 비슷한 비용으로 이동하는 것입니다.
| 방식 | 조회 비용 | export에서의 의미 |
|---|---|---|
| offset paging | 뒤 페이지로 갈수록 앞의 row를 더 많이 건너뜁니다. | 전체 순회가 길어질수록 응답 시간이 흔들립니다. |
| cursor paging | 마지막으로 읽은 기준 이후를 이어서 조회합니다. | 페이지 경계마다 비용을 더 예측 가능하게 만들 수 있습니다. |
cursor에는 정렬 기준이 중요합니다. created_at만 사용하면 같은 시간에 생성된 row 사이에서 순서가 불안정해질 수 있습니다. 그래서 ledger_id를 함께 사용해 동일 timestamp 안에서도 다음 페이지 기준을 안정적으로 잡았습니다.
이 기준을 잡을 때는 조회 조건도 함께 확인했습니다. 다음 페이지는 “마지막으로 읽은 시각보다 큰 row”와 “같은 시각이지만 마지막 id보다 큰 row”를 함께 봐야 합니다. 정렬 컬럼과 cursor 조건이 어긋나면 export가 빨라져도 row 누락이나 중복이 생길 수 있습니다. 이 작업에서 cursor는 성능 최적화이면서 동시에 전체 순회 정확성을 지키는 기준이었습니다.
반복 lookup은 export 단위로 재사용했습니다
대용량 export에서는 메인 query만 느린 것이 아닙니다. 페이지마다 따라붙는 작은 lookup이 전체 시간을 불안정하게 만드는 경우가 많습니다. 조직, 파트너, 트라이얼 이름처럼 export row를 만들기 위해 필요한 보조 데이터가 매 페이지마다 반복 조회되면, 개별 쿼리는 작아도 전체 export에서는 큰 비용이 됩니다.
그래서 export 전체에서 재사용 가능한 lookup은 bounded cache로 묶었습니다. organizationName 필터도 export 시작 시점에 한 번만 계산해서 넘기도록 바꿨습니다. 이 방식은 단순히 쿼리 수를 줄이는 최적화가 아니라, page마다 export 시간이 튀는 변수를 줄이는 작업이었습니다. export는 한 요청 안에서 같은 보조 데이터를 반복해서 조립하는 경우가 많기 때문에, 작은 조회라도 반복 횟수가 커지면 응답 수명에 직접 영향을 줍니다.
여기서 같이 발견한 위험도 있었습니다. organizationName 매칭 결과가 0건일 때 조건이 빠지면 전체 ledger가 내려갈 수 있었습니다. 화면 조회에서는 빈 목록으로 끝날 문제가 export에서는 큰 범위의 데이터 다운로드로 이어질 수 있습니다. 그래서 매칭 결과가 0건이면 빈 CursorPage를 즉시 반환하도록 처리했습니다. 성능을 줄이려다 필터의 의미가 바뀌면, export에서는 장애보다 더 위험한 데이터 범위 문제가 됩니다.
다운로드 성공을 판단하는 관측 항목
일반 API에서는 p95 latency와 error rate만 봐도 충분한 경우가 많습니다. 하지만 export는 응답 시간이 긴 작업이고, 조회·직렬화·압축·전송이 모두 섞입니다. 따라서 “느리다”는 말만으로는 어디가 문제인지 알 수 없습니다.
export 경로에서는 다음 지표를 따로 봐야 했습니다.
| 지표 | 확인하려는 것 |
|---|---|
| 첫 byte 전송까지의 시간 | 사용자가 다운로드 시작을 체감하기까지 걸리는 시간 |
| page별 조회 시간 | 뒤 페이지로 갈수록 조회 비용이 커지는지 여부 |
| row 직렬화 시간 | CSV escape, 날짜 포맷, null 처리 비용이 누적되는지 여부 |
| flush 간격과 write 실패 | 네트워크 write 비용과 중간 실패 위치 |
| client disconnect | 사용자 취소와 서버 오류를 구분할 수 있는지 여부 |
client disconnect를 분리한 것도 이 기준 때문입니다. 사용자가 창을 닫아서 발생한 IOException과 서버가 ZIP을 끝까지 쓰지 못한 오류를 같은 장애로 집계하면 운영자는 더 많은 로그를 보지만 더 적은 정보를 얻게 됩니다. export에서는 실패를 많이 남기는 것보다 실패의 성격을 나누는 것이 더 중요했습니다.
그래서 로그는 “export 실패” 하나로 묶지 않고, 가능한 한 단계별로 남기는 쪽이 더 유용했습니다. page query가 늦어진 것인지, row 직렬화 중 예외가 난 것인지, flush 이후 client disconnect가 발생한 것인지가 구분되어야 다음 대응이 달라집니다.
검증은 “파일이 내려왔다”에서 끝내지 않았습니다
이번 변경에서 필요한 검증은 단순 다운로드 성공이 아니었습니다. 브라우저가 파일을 받은 것처럼 보여도 ZIP이 정상 종료되지 않았을 수 있기 때문입니다.
그래서 검증 기준을 다음처럼 나눴습니다.
- 정상 데이터가 있을 때 압축 해제가 가능한지 확인합니다.
- 빈 데이터에서도 정상 ZIP과 header가 생성되는지 확인합니다.
- cursor page 경계에서 row 누락이나 중복이 없는지 확인합니다.
- write 도중
IOException이 발생했을 때 서버 오류와 client disconnect가 구분되는지 확인합니다. - 필터 결과가 0건인 경우 전체 데이터가 내려가지 않는지 확인합니다.
- 생성된 ZIP을 실제로 열어 보고, CSV header와 row 수가 조회 조건과 맞는지 확인합니다.
핵심은 export의 성공 기준을 다시 정의한 것입니다. export는 응답을 시작했다고 성공이 아닙니다. 정확한 범위의 데이터를 마지막 종료 지점까지 안전하게 내려주는 것까지가 성공입니다. 이 기준을 세워야 다운로드 시작, 파일 완성, 데이터 범위 정확성을 서로 다른 검증 항목으로 다룰 수 있습니다.
이 선택의 비용도 남았습니다
이 구조가 항상 가장 좋은 답은 아닙니다. HttpServletResponse에 직접 write하는 방식은 요청 처리 thread를 더 오래 붙잡습니다. 그래서 export 동시성이 훨씬 높거나 생성 시간이 수 분 이상으로 길어지는 환경이라면, 비동기 job으로 파일을 생성하고 다운로드 링크를 제공하는 구조가 더 맞을 수 있습니다. 이번 선택은 즉시 다운로드 UX를 유지해야 했고, 문제의 핵심이 초장기 배치가 아니라 servlet async timeout 경계에서 ZIP이 정상 종료되지 않는 데 있었기 때문에 가능한 선택이었습니다. 이 trade-off를 보려면 성공률뿐 아니라 동시 export 수, thread 점유 시간, client disconnect 비율을 같이 봐야 합니다.
이번 선택은 “sync export가 정답”이라는 결론이 아니었습니다. 당시 요구사항에서는 즉시 다운로드 UX를 유지해야 했고, 프론트엔드 계약을 바꾸지 않는 것이 중요했습니다. 또한 문제는 초장기 batch가 아니라 수십 초 안에서 ZIP이 정상 종료되지 않는 구조적 결함에 가까웠습니다. 그래서 현재 경로를 유지하면서 응답 수명과 조회 비용을 먼저 정리하는 편이 더 좁고 안전한 변경이었습니다.
다시 같은 문제가 생기지 않게 둔 기준
이 문제를 특정 helper 하나의 버그로만 보면, 다음 export endpoint에서 같은 문제가 반복될 수 있습니다. 그래서 구현보다 기준을 남기는 것이 더 중요했습니다.
대용량 export는 단순 다운로드 기능처럼 보이지만 실제로는 조회, 직렬화, 압축, 네트워크 전송이 이어지는 작은 파이프라인입니다. 어느 한 구간이 흔들리면 사용자는 “파일이 깨졌다”는 하나의 증상으로만 봅니다. 서버는 그 증상을 page 조회 지연, 압축 종료 실패, flush 이후 write 실패, client disconnect처럼 더 작은 단계로 나눠 설명할 수 있어야 합니다. 그래야 다음 export 기능에서도 timeout을 늘리는 방식으로 되돌아가지 않습니다.
운영에서 바뀐 질문
이번 문제에서 가장 중요한 전환은 “ZIP이 왜 깨졌는가”에서 “응답이 왜 ZIP을 끝까지 쓰지 못했는가”로 질문을 바꾼 것이었습니다. 질문이 바뀌자 해법도 포맷 수정이 아니라 response lifecycle, cursor paging, lookup 재사용으로 나뉘었습니다.
운영에서 보는 기준도 달라졌습니다. 다운로드가 시작됐는지만 보지 않고, page별 조회 시간이 뒤로 갈수록 커지는지, flush 이후 write 실패가 어디서 발생하는지, client disconnect와 서버 오류가 구분되는지, 마지막 ZIP 종료 지점까지 도달했는지를 함께 봅니다.
대용량 export에서 빠른 첫 byte는 사용자 체감에 중요하지만, 성공 기준은 거기서 끝나지 않습니다. ZIP처럼 마지막 구조가 필요한 포맷에서는 마지막 write까지 도달했는지, client disconnect를 서버 오류와 분리했는지, 빈 결과와 부분 실패를 다르게 기록했는지까지 봐야 합니다. 이번 작업은 export를 “빨리 응답하는 API”로 보는 대신, 사용자가 받은 파일이 끝까지 열리는 결과물인지 확인하는 쪽으로 기준을 옮긴 작업이었습니다.