자바 코드는 운영체제 위에서 바로 실행되지 않습니다. .java 파일은 먼저 바이트코드로 컴파일되고, JVM은 그 바이트코드를 로드한 뒤 인터프리터와 JIT 컴파일러를 통해 실행합니다. 객체는 힙에 쌓이고, 더 이상 참조되지 않는 객체는 GC가 회수합니다.
그래서 JVM을 이해한다는 것은 용어를 외우는 일이 아닙니다. 애플리케이션에서 보이는 응답 지연, GC pause, 메모리 증가, 클래스 로딩 문제를 코드가 실제로 실행되는 단계와 연결해서 읽을 수 있게 되는 것에 가깝습니다.
JDK, JRE, JVM은 역할이 다릅니다
자바 실행 흐름을 보기 전에 세 용어를 먼저 나누는 편이 좋습니다.
| 구분 | 역할 | 대표 구성 요소 |
|---|---|---|
| JDK | 자바 개발 도구 | javac, javap, debugger, JRE |
| JRE | 자바 실행 환경 | JVM, 표준 라이브러리, 실행에 필요한 파일 |
| JVM | 바이트코드를 실제 플랫폼에서 실행하는 가상 머신 | Class Loader, Runtime Data Area, Execution Engine, GC |
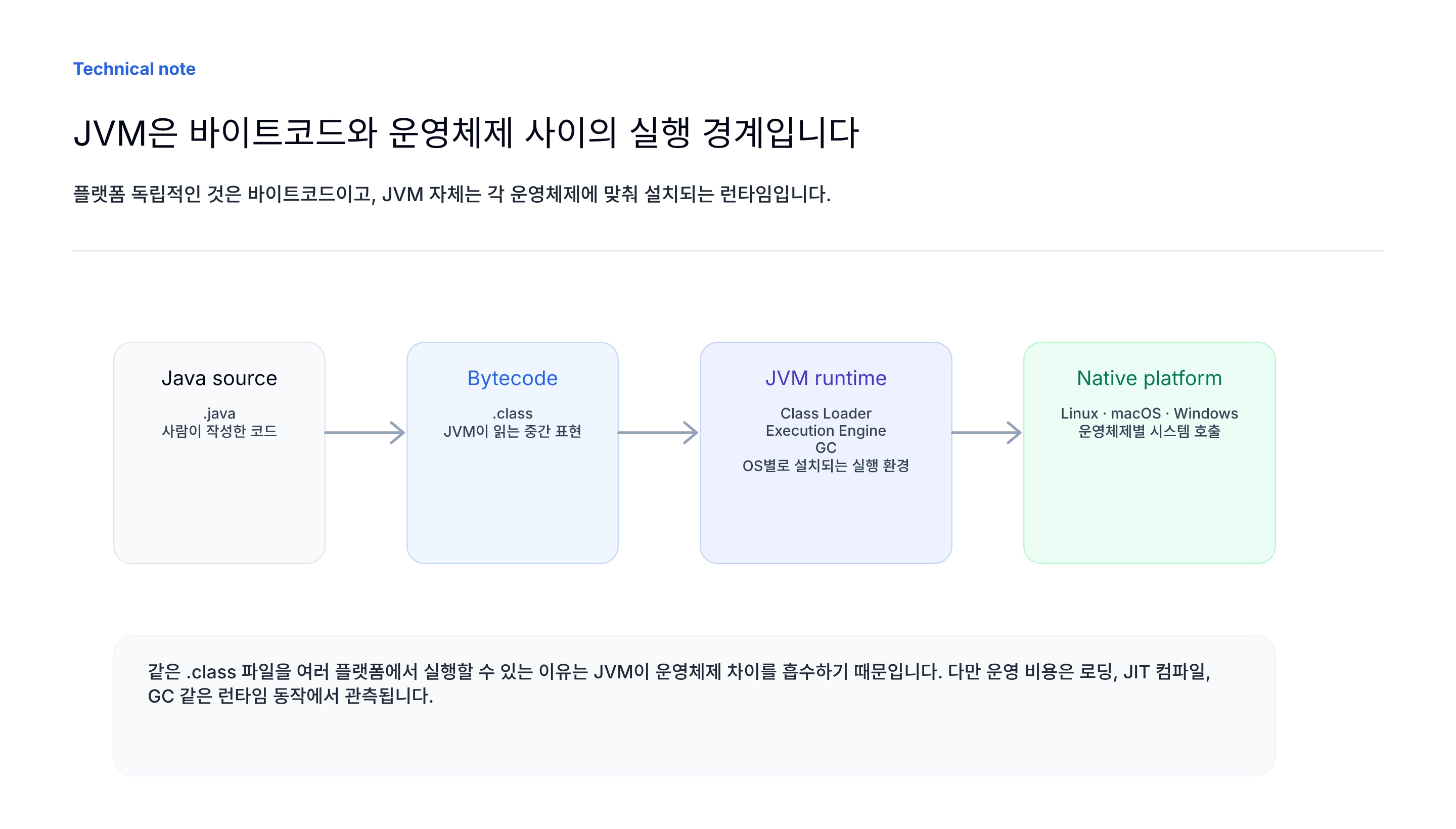
자바가 “Write Once, Run Anywhere”라고 말할 수 있는 이유는 소스 코드가 운영체제와 CPU에 직접 맞춰 컴파일되지 않기 때문입니다. 자바 코드는 바이트코드라는 중간 표현으로 컴파일되고, 각 운영체제에 맞는 JVM이 이 바이트코드를 실행합니다.
최근 JDK 배포에서는 예전처럼 JRE를 별도 설치 단위로 명확히 나누지 않는 경우도 많습니다. 그래도 개념을 나눠 보면 도움이 됩니다. JDK는 개발과 빌드까지 포함한 도구 묶음이고, JVM은 바이트코드를 실제 머신 위에서 실행하는 런타임의 핵심입니다.
자바 프로그램은 네 단계를 거쳐 실행됩니다
전체 흐름은 아래처럼 볼 수 있습니다.

javac가.java파일을.class바이트코드로 컴파일합니다.- Class Loader가 필요한 클래스를 찾아 JVM 메모리에 로드합니다.
- Execution Engine이 바이트코드를 해석하거나 JIT 컴파일합니다.
- GC가 힙에 쌓인 객체 중 더 이상 참조되지 않는 객체를 회수합니다.
이 흐름을 알아야 JVM 문제를 층위별로 좁힐 수 있습니다. 클래스가 없다는 오류는 실행 엔진이 아니라 클래스 로딩 쪽 문제일 가능성이 높고, Full GC가 반복된다면 컴파일보다 객체 생명주기와 힙 구조를 먼저 봐야 합니다.
javac는 소스 코드를 바이트코드로 바꿉니다
컴파일 단계에서 javac는 사람이 작성한 .java 파일을 JVM이 이해할 수 있는 .class 파일로 변환합니다. 이 .class 파일은 사람이 읽기 좋은 자바 코드가 아니라 바이너리 형식의 바이트코드입니다.
public class Hello {
public void print() {
System.out.println("hello");
}
}javap로 역어셈블하면 바이트코드를 사람이 읽을 수 있는 형태로 볼 수 있습니다.
public void print();
Code:
0: getstatic #7
3: ldc #13
5: invokevirtual #15
8: returnIDE에서 .class 파일을 열면 자바 코드처럼 보일 수 있습니다. 하지만 그것은 IDE가 역컴파일해 보여주는 결과입니다. 실제 .class 파일은 JVM 명령어와 constant pool 정보를 담은 바이너리입니다.
바이트코드는 symbolic reference를 사용합니다
바이트코드는 처음부터 실제 메모리 주소를 직접 들고 있지 않습니다. 대신 클래스, 필드, 메서드를 이름 기반 참조로 표현합니다.
| 참조 방식 | 의미 |
|---|---|
| Symbolic Reference | 클래스, 필드, 메서드를 이름으로 가리키는 참조 |
| Direct Reference | JVM이 런타임에 해석한 실제 메모리 위치 또는 내부 구조 참조 |
클래스 로딩과 링킹 과정에서 JVM은 symbolic reference를 실제 실행 가능한 참조로 바꿉니다. 그래서 컴파일된 .class 파일만 있다고 바로 실행되는 것이 아니라, JVM이 클래스를 로드하고 검증하고 연결하는 과정이 필요합니다.
클래스 로딩은 “파일 읽기”보다 더 넓은 과정입니다
Class Loader는 필요한 클래스를 찾아 JVM으로 가져옵니다. 하지만 클래스 로딩은 단순히 .class 파일을 읽는 것에서 끝나지 않습니다.
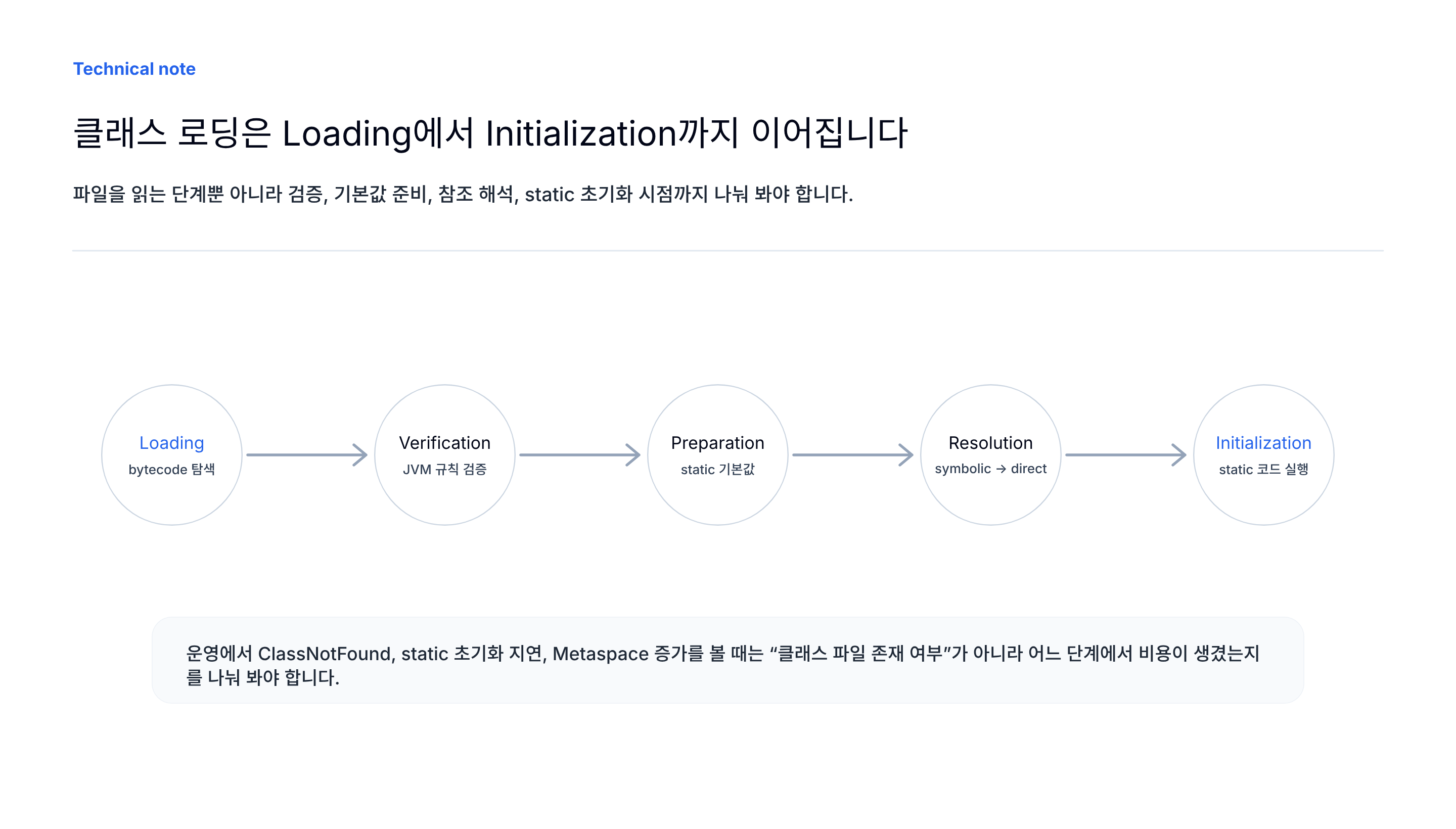
클래스는 보통 세 단계를 거쳐 준비됩니다.
| 단계 | 역할 |
|---|---|
| Loading | 클래스 바이트코드를 찾아 메모리에 올림 |
| Linking | 검증, 기본값 준비, symbolic reference 해석 |
| Initialization | static 필드와 static block을 실제 코드 기준으로 초기화 |
Linking은 다시 verification, preparation, resolution으로 나눌 수 있습니다.
- Verification: 바이트코드가 JVM 규칙을 위반하지 않는지 검증합니다.
- Preparation: static 필드에 기본값을 할당합니다.
- Resolution: symbolic reference를 직접 참조로 해석합니다.
여기서 자주 헷갈리는 지점은 preparation과 initialization입니다. static int value = 10이 있다면 preparation에서는 기본값 0이 잡히고, initialization 단계에서 코드에 작성한 값 10이 반영됩니다.
ClassLoader는 위임 모델로 동작합니다
자바의 ClassLoader는 계층 구조와 위임 모델을 가집니다. 애플리케이션 ClassLoader가 어떤 클래스를 로드하려고 할 때, 먼저 부모 ClassLoader에게 요청을 위임합니다. 부모가 찾지 못하면 그때 자식이 직접 찾습니다.
이 모델은 보안과 일관성에 중요합니다. 예를 들어 애플리케이션이 임의로 java.lang.String을 만들어 표준 클래스를 바꿔치기하는 일을 막는 데 도움이 됩니다.
Java 8까지는 Bootstrap, Extension, Application ClassLoader라는 구분이 자주 사용됐습니다. Java 9 이후 모듈 시스템이 들어오면서 Extension ClassLoader 대신 Platform ClassLoader라는 표현이 더 자연스럽습니다.
| ClassLoader | 역할 |
|---|---|
| Bootstrap | JDK 핵심 클래스 로드 |
| Platform | 표준 플랫폼 모듈 일부 로드 |
| Application | 애플리케이션 classpath/module-path 클래스 로드 |
| Custom | 프레임워크, 플러그인, 컨테이너 등이 직접 정의한 로딩 전략 |
Runtime Data Area는 비용이 쌓이는 장소입니다
JVM은 프로그램 실행 중 필요한 데이터를 Runtime Data Area에 나눠 저장합니다.

크게 보면 모든 스레드가 공유하는 영역과 스레드마다 따로 가지는 영역이 있습니다.
모든 스레드가 공유하는 영역
| 영역 | 저장되는 데이터 | 운영에서 보는 문제 |
|---|---|---|
| Heap | 객체, 배열, 문자열 등 | GC pause, OutOfMemoryError, allocation 증가 |
| Method Area / Metaspace | 클래스 메타데이터, 메서드 정보, constant pool | 동적 클래스 로딩, proxy 증가, ClassLoader 누수 |
HotSpot JVM 기준으로 Java 8 이후 클래스 메타데이터는 주로 Metaspace에 저장됩니다. Metaspace는 heap이 아니라 native memory 영역을 사용합니다. 따라서 heap이 충분해 보여도 Metaspace가 계속 증가하면 별도의 메모리 문제가 될 수 있습니다.
스레드마다 따로 가지는 영역
| 영역 | 역할 |
|---|---|
| JVM Stack | 메서드 호출마다 frame을 쌓고, 지역 변수와 operand stack을 관리 |
| PC Register | 현재 실행 중인 JVM 명령어 위치를 가리킴 |
| Native Method Stack | 네이티브 메서드 실행에 필요한 스택 |
스레드가 많아지면 heap만 보는 것으로는 부족합니다. 각 스레드는 stack을 가지기 때문에 스레드 수가 과도하게 늘면 native memory에도 영향을 줍니다. 응답 지연이 발생했을 때 thread dump를 같이 보는 이유도 여기에 있습니다.
Execution Engine은 해석과 컴파일을 함께 사용합니다
클래스가 로드되고 메모리에 준비되면 Execution Engine이 바이트코드를 실행합니다.
JVM은 처음부터 모든 코드를 네이티브 코드로 컴파일하지 않습니다. 보통은 인터프리터로 시작하고, 자주 실행되는 코드 경로를 JIT 컴파일러가 네이티브 코드로 바꿉니다.
| 방식 | 특징 | 장점 | 주의점 |
|---|---|---|---|
| Interpreter | 바이트코드를 한 명령씩 해석 | 시작이 빠름 | 반복 실행 비용이 큼 |
| JIT Compiler | 자주 실행되는 코드를 네이티브 코드로 컴파일 | 반복 경로가 빨라짐 | warm-up 시간이 필요함 |
JIT이 중요한 이유는 운영에서 “처음 몇 번은 느리다가 시간이 지나며 빨라지는” 현상을 설명해주기 때문입니다. HotSpot은 자주 실행되는 메서드와 루프를 관찰하고, 일정 기준을 넘으면 더 빠른 네이티브 코드로 컴파일합니다.
그래서 성능 테스트를 할 때는 애플리케이션이 충분히 warm-up 되었는지 확인해야 합니다. 막 시작한 JVM에서 측정한 p95와 일정 시간 트래픽을 받은 뒤의 p95는 다르게 나올 수 있습니다.
GC는 메모리를 자동으로 치우지만 비용이 없지는 않습니다
자바는 더 이상 참조되지 않는 객체를 GC가 회수합니다. 이 점은 개발자가 직접 메모리를 해제하지 않아도 된다는 장점이지만, GC가 비용 없이 동작한다는 뜻은 아닙니다.
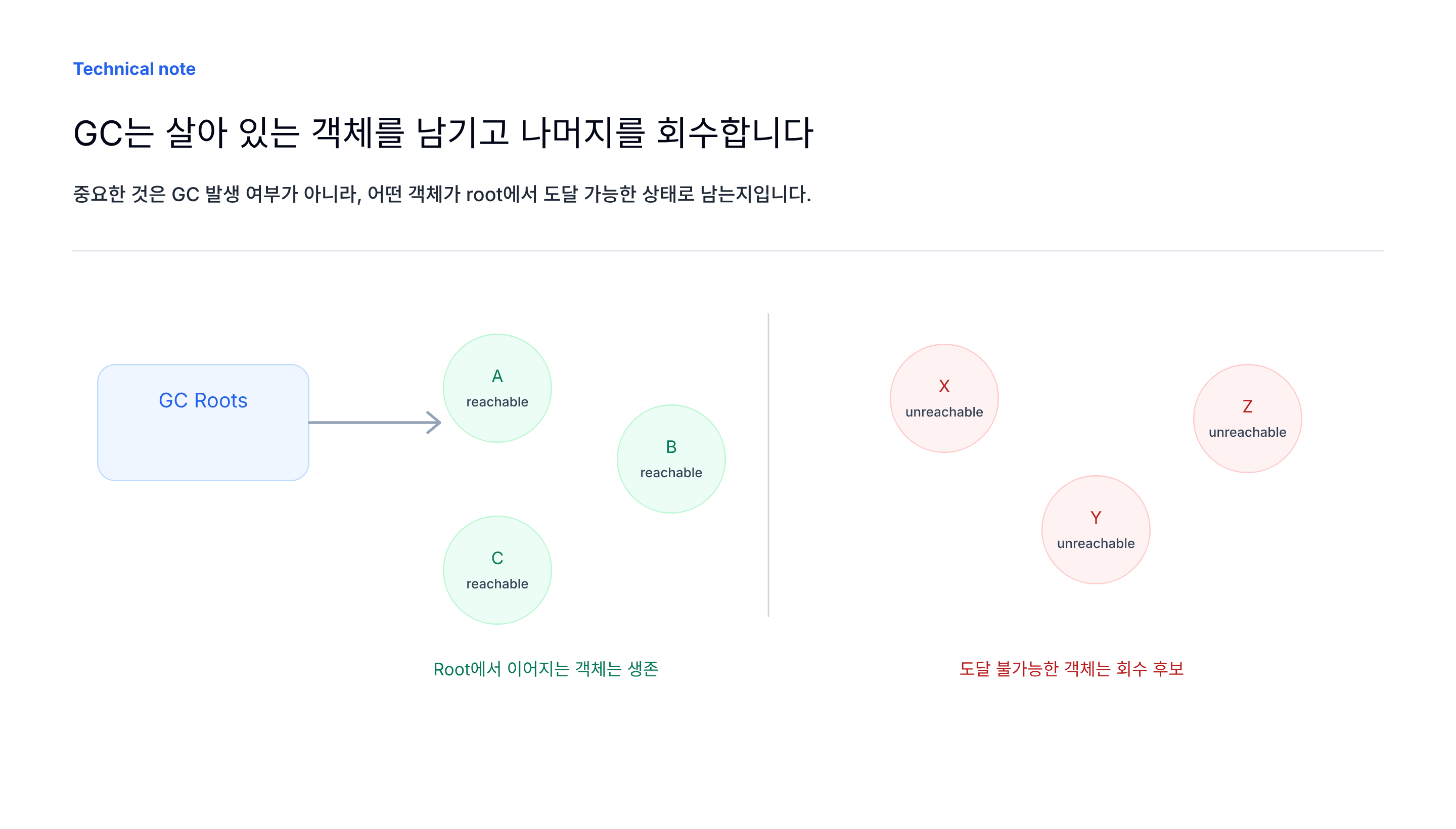
GC를 이해할 때 가장 먼저 봐야 하는 개념은 reachability입니다. 어떤 객체가 GC Root에서 도달 가능하다면 살아 있는 객체로 간주됩니다. 도달할 수 없다면 회수 대상이 됩니다.
대표적인 GC Root는 다음과 같습니다.
- 실행 중인 스레드의 stack frame에서 참조하는 객체
- static 필드가 참조하는 객체
- JNI 또는 native 영역에서 참조하는 객체
- JVM 내부 구조가 참조하는 객체
Stop-The-World는 애플리케이션 지연으로 보입니다
GC 중 일부 단계에서는 애플리케이션 스레드가 멈춥니다. 이를 Stop-The-World라고 부릅니다. GC 종류에 따라 멈추는 시간과 방식은 다르지만, 운영에서는 이 시간이 응답 지연으로 나타날 수 있습니다.
Mark, Sweep, Compact는 목적이 다릅니다
- Mark: 살아 있는 객체를 찾습니다.
- Sweep: 죽은 객체가 차지하던 공간을 회수합니다.
- Compact: 흩어진 빈 공간을 정리해 큰 연속 공간을 확보합니다.
Compact는 메모리 단편화를 줄이는 데 도움이 되지만, 객체 이동과 참조 갱신이 필요하므로 비용이 큽니다.
세대별 GC는 객체 생명주기 가정에서 출발합니다
대부분의 애플리케이션 객체는 짧게 살고 사라집니다. 요청 처리 중 만들어진 DTO, 임시 List, 문자열 조합 결과는 응답이 끝나면 필요 없어지는 경우가 많습니다. 세대별 GC는 이 특성에서 출발합니다.
| 영역 | 역할 |
|---|---|
| Eden | 새 객체가 처음 할당되는 공간 |
| Survivor | Young GC를 살아남은 객체가 잠시 머무는 공간 |
| Old | 여러 번 살아남아 오래 유지될 가능성이 큰 객체가 이동하는 공간 |
Young GC가 자주 발생한다고 해서 항상 문제는 아닙니다. 짧게 살고 사라지는 객체가 많고 pause가 짧다면 정상적인 패턴일 수 있습니다. 반대로 Old 영역이 GC 이후에도 계속 증가하거나 Full GC가 반복되면 오래 살아남는 객체가 누적되고 있는지 확인해야 합니다. 이때는 절대적인 횟수보다 요청량, allocation rate, pause time, Old 영역 회수 여부를 같은 시간축에 놓고 봅니다. 같은 Young GC라도 사용자 지연과 겹치는지, 배포 직후 warm-up 구간에서만 튀는지에 따라 해석이 달라집니다.
운영에서 JVM을 볼 때는 지표를 연결해야 합니다
JVM 지표는 단독으로 보면 오해하기 쉽습니다. heap 사용량이 높다고 항상 메모리 누수는 아니고, GC가 발생했다고 항상 GC가 병목도 아닙니다. 요청량, 객체 생성량, thread 상태를 함께 봐야 합니다.
자주 보는 항목은 다음과 같습니다.
| 지표 | 확인하려는 것 |
|---|---|
| heap used / committed / max | 힙 사용량이 요청량과 함께 움직이는지 |
| allocation rate | 객체가 얼마나 빠르게 생성되는지 |
| Young GC / Full GC 빈도 | 회수 주기와 pause 패턴 |
| GC pause time | 사용자 응답 지연과 겹치는지 |
| Old 영역 사용량 | GC 이후에도 살아남는 객체가 누적되는지 |
| thread count / blocked thread | 락 대기, I/O 대기, thread pool 포화 여부 |
| Metaspace 사용량 | 동적 클래스 로딩이나 ClassLoader 누수 가능성 |
같은 heap 증가라도 해석은 달라질 수 있습니다. 요청량이 늘며 Young 영역 사용량이 증가하는 것과, 요청량은 그대로인데 Old 영역이 계속 증가하는 것은 전혀 다른 문제입니다.
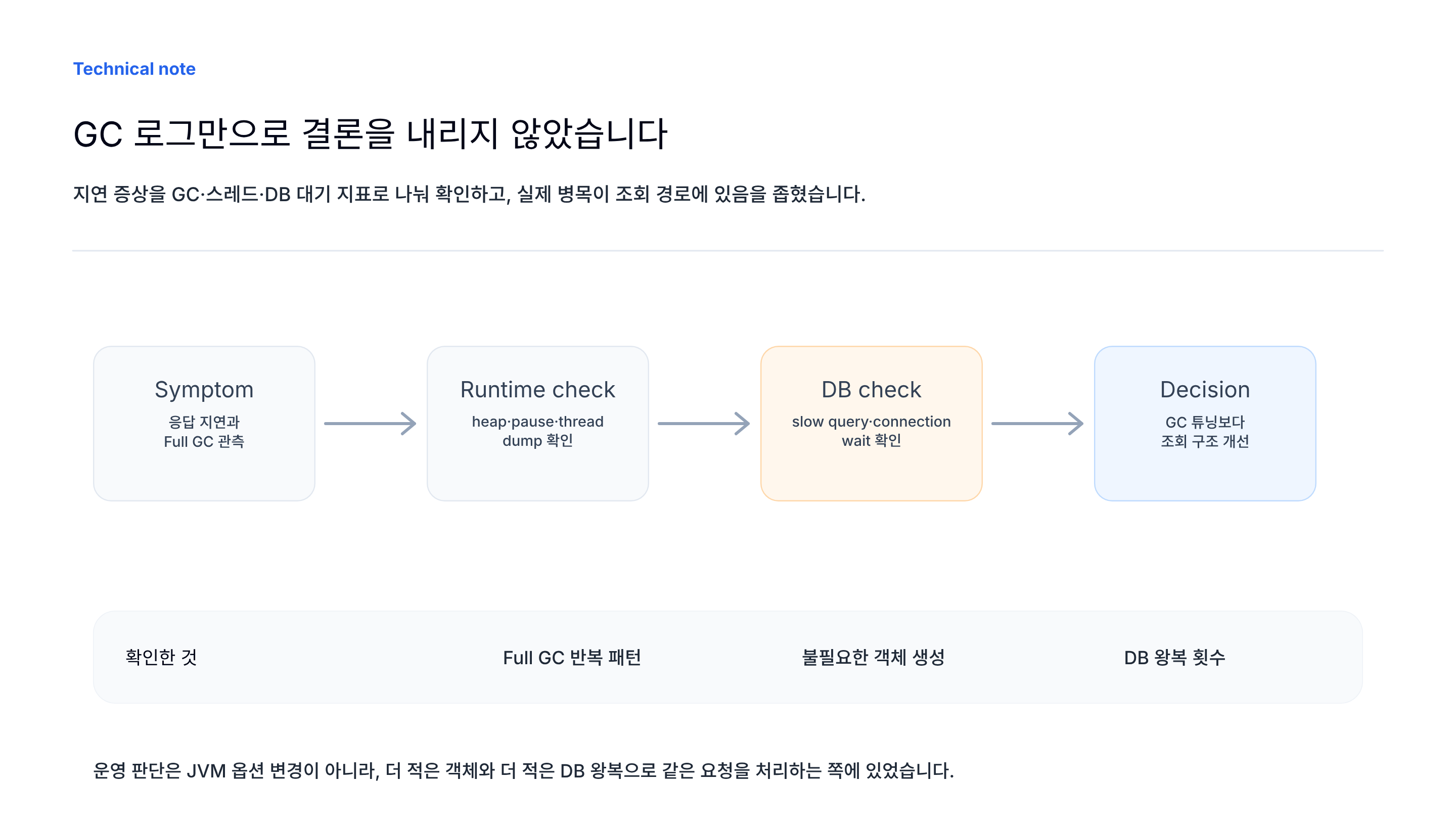
JVM 성능 문제는 옵션보다 원인 분리가 먼저입니다
JVM 문제가 보이면 heap 크기를 늘리거나 GC 옵션을 바꾸고 싶어집니다. 하지만 옵션 조정은 마지막에 가까워야 합니다. 먼저 병목이 CPU인지, allocation인지, lock인지, I/O 대기인지 나눠야 합니다.
1. 응답 지연이 CPU 사용률 증가와 함께 나타나는지 확인한다.
2. allocation rate와 GC pause time을 확인한다.
3. GC 이후 Old 영역이 줄어드는지 확인한다.
4. thread dump로 RUNNABLE, WAITING, BLOCKED 비율을 확인한다.
5. DB connection pool, 외부 API, lock wait 같은 대기 지점을 확인한다.
6. 마지막에 heap 크기와 GC 옵션 조정을 검토한다.예를 들어 thread count가 늘고 응답이 느리다면 GC보다 thread dump가 먼저일 수 있습니다. 많은 스레드가 WAITING이라면 DB connection pool이나 외부 API 대기일 수 있고, BLOCKED가 많다면 synchronized 구간이나 공유 자원 경쟁을 의심해야 합니다.
메모리도 마찬가지입니다. heap이 순간적으로 올라갔다가 GC 후 내려간다면 요청 처리 중 생긴 임시 객체일 수 있습니다. 반대로 GC 후에도 Old 영역이 계속 올라간다면 heap dump를 떠서 어떤 객체가 살아남는지 확인해야 합니다.
JVM을 이해하면 코드 리뷰 기준도 달라집니다
JVM 관점으로 코드를 보면 단순히 메서드가 빠른지만 보지 않게 됩니다. 이 코드가 어떤 객체를 얼마나 만들고, 그 객체가 얼마나 오래 참조되는지 보게 됩니다.
예를 들어 요청마다 큰 List를 만들고 대부분 버리는 코드는 CPU보다 allocation rate를 먼저 올릴 수 있습니다. Young 영역에서 바로 회수된다면 pause가 짧게 반복될 수 있고, 일부 객체가 캐시나 static 참조에 걸려 오래 살아남으면 Old 영역 압박으로 이어질 수 있습니다.
캐시도 마찬가지입니다. 캐시는 DB 호출을 줄이지만 JVM 안에서는 오래 살아남는 객체를 의도적으로 늘리는 선택입니다. 캐시 크기, 만료 정책, key cardinality가 정리되지 않으면 성능 최적화가 메모리 문제로 바뀔 수 있습니다.
응답 지연을 JVM 안에서 좁히는 순서
자바 코드는 javac를 거쳐 바이트코드가 되고, Class Loader가 이를 로드하고 연결한 뒤, Execution Engine이 인터프리터와 JIT으로 실행합니다. 실행 중 만들어진 객체는 Runtime Data Area에 쌓이고, GC는 더 이상 참조되지 않는 객체를 회수합니다.
운영에서 JVM을 볼 때 필요한 것은 용어 암기가 아니었습니다. 클래스 로딩 문제인지, JIT warm-up 문제인지, heap allocation 문제인지, thread 대기 문제인지 먼저 나눠야 합니다. 같은 응답 지연이라도 원인이 다르면 확인할 지표도 달라집니다. 배포 직후에만 느린 요청, 특정 요청에서만 늘어나는 allocation, thread dump에서 보이는 대기 상태는 서로 다른 층위의 신호입니다. 특히 롤링 배포 직후 새 인스턴스가 차가운 상태로 트래픽을 받는 구간은 readiness와 warm-up을 함께 봐야 합니다.
- 바이트코드는 플랫폼 독립적인 중간 표현이고, JVM은 플랫폼에 맞춰 이를 실행합니다.
- 클래스 로딩은 loading, linking, initialization을 거치며 static 초기화 시점까지 포함합니다.
- Heap, Metaspace, Stack은 서로 다른 비용을 가지며 운영 지표도 다르게 봐야 합니다.
- JIT은 자주 실행되는 코드를 빠르게 만들지만 warm-up과 측정 조건을 함께 고려해야 합니다.
- GC는 자동 메모리 관리 장치지만 pause와 객체 생명주기 비용을 남깁니다.
JVM 튜닝은 옵션을 먼저 바꾸는 일이 아니라, 코드 실행 흐름과 런타임 지표를 연결해 병목을 좁히는 일입니다. 응답 지연이 보이면 GC 로그, heap 사용량, thread 상태, JIT warm-up 구간을 같은 시간축에 놓고 봐야 합니다. JVM은 추상적인 실행 환경이 아니라 애플리케이션 비용이 실제로 쌓이는 장소입니다. 실행 흐름을 알고 나면, 메모리 증가나 지연을 “서버가 느리다”가 아니라 코드와 런타임이 만난 결과로 읽을 수 있습니다.